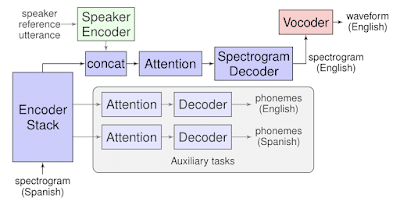
Translatotron proves that a single sequence-to-sequence AI model can directly translate speech from one language into another. In their research paper, the team demonstrated the new speech translation model and successfully obtained high translation quality on two Spanish-to-English datasets. Also Read: Top 3 Major Limitations of Artificial Intelligence (AI) If we go a little deeper, speech-to-speech translation systems usually consists of three components:
Speech Recognition: It used to convert the source speech into text. Machine Translation: It is used for translating the converted text into the target language. Text-to-Speech Synthesis (TTS): It is used to produce speech in the target language from the translated text.
There are many successful speech-to-speech translation products such as Google Translate powered by such systems. Google engineers have been working on this project for almost three years. The story started in 2016 when researchers demonstrated the practicability of using a single sequence-to-sequence model for speech-to-text translation. It also made researchers realized the need for end-to-end speech translation models Later, in 2017, the Google AI team showed that such these models can outperform the conventional cascade models. Not only Google, but recently many other proposals have also been made for improving end-to-end speech-to-text translation models. Unlike cascaded systems, Translatotron doesn’t rely on an intermediate text representation in either language. It’s based on a sequence-to-sequence network that takes source spectrograms as input and then generates spectrograms of the translated text in the target language. The new end-to-end speech translation model works on two separately trained components:
Neural vocoder: It converts output spectrograms to time-domain waveforms. Speaker encoder: It maintains the source speaker’s voice in the synthesized translated speech.
The Google AI engineers validated Translatotron’s translation quality by measuring the BLEU (bilingual evaluation understudy) score, computed with text converted by a speech recognition system. The results might lag behind a traditional cascade system but the team has managed to demonstrate the usefulness of the end-to-end direct speech-to-speech translation. Also Read: Google Launches AI Platform For Developers and Data Scientists Translatotron retains the original vocal characteristics in the translated speech by including a speaker encoder network and makes the translated speech sound natural. The engineers concluded that Translatotron is the first end-to-end model that can directly translate speech from one language into speech in another language and can retain the source voice in the translated speech. They are considering this as a starting point for future research on end-to-end speech-to-speech translation systems.